Kernelized Locality-Sensitive Hashing Page


Brian Kulis (1) and Kristen Grauman (2)
(1) UC Berkeley EECS and ICSI, Berkeley, CA
(2) University of Texas, Department of Computer Sciences, Austin, TX
Introduction
Fast indexing and search for large databases is critical to content-based image and video retrieval---particularly given the ever-increasing availability of visual data in a variety of interesting domains, such as scientific image data, community photo collections on the Web, news photo collections, or surveillance archives. The most basic but essential task in image search is the "nearest neighbor" problem: to take a query image and accurately find the examples that are most similar to it within a large database. A naive solution to finding neighbors entails searching over all n database items and sorting them according to their similarity to the query, but this becomes prohibitively expensive when n is large or when the individual similarity function evaluations are expensive to compute. For vision applications, this complexity is amplified by the fact that often the most effective representations are high-dimensional or structured, and best known distance functions can require considerable computation to compare a single pair of objects.
To make large-scale search practical, vision researchers have recently explored approximate similarity search techniques, most notably locality-sensitive hashing (Indyk and Motwani 1998, Charikar 2002), where a predictable loss in accuracy is sacrificed in order to allow fast queries even for high-dimensional inputs. In spite of hashing's success for visual similarity search tasks, existing techniques have some important restrictions. Current methods generally assume that the data to be hashed comes from a multidimensional vector space, and require that the underlying embedding of the data be explicitly known and computable. For example, LSH relies on random projections with input vectors; spectral hashing (Weiss et al. NIPS 2008) assumes vectors with a known probability distribution.
This is a problematic limitation, given that many recent successful vision results employ kernel functions for which the underlying embedding is known only implicitly (i.e., only the kernel function is computable). It is thus far impossible to apply LSH and its variants to search data with a number of powerful kernels---including many kernels designed specifically for image comparisons, as well as some basic well-used functions like a Gaussian RBF. Further, since visual representations are often most naturally encoded with structured inputs (e.g., sets, graphs, trees), the lack of fast search methods with performance guarantees for flexible kernels is inconvenient.
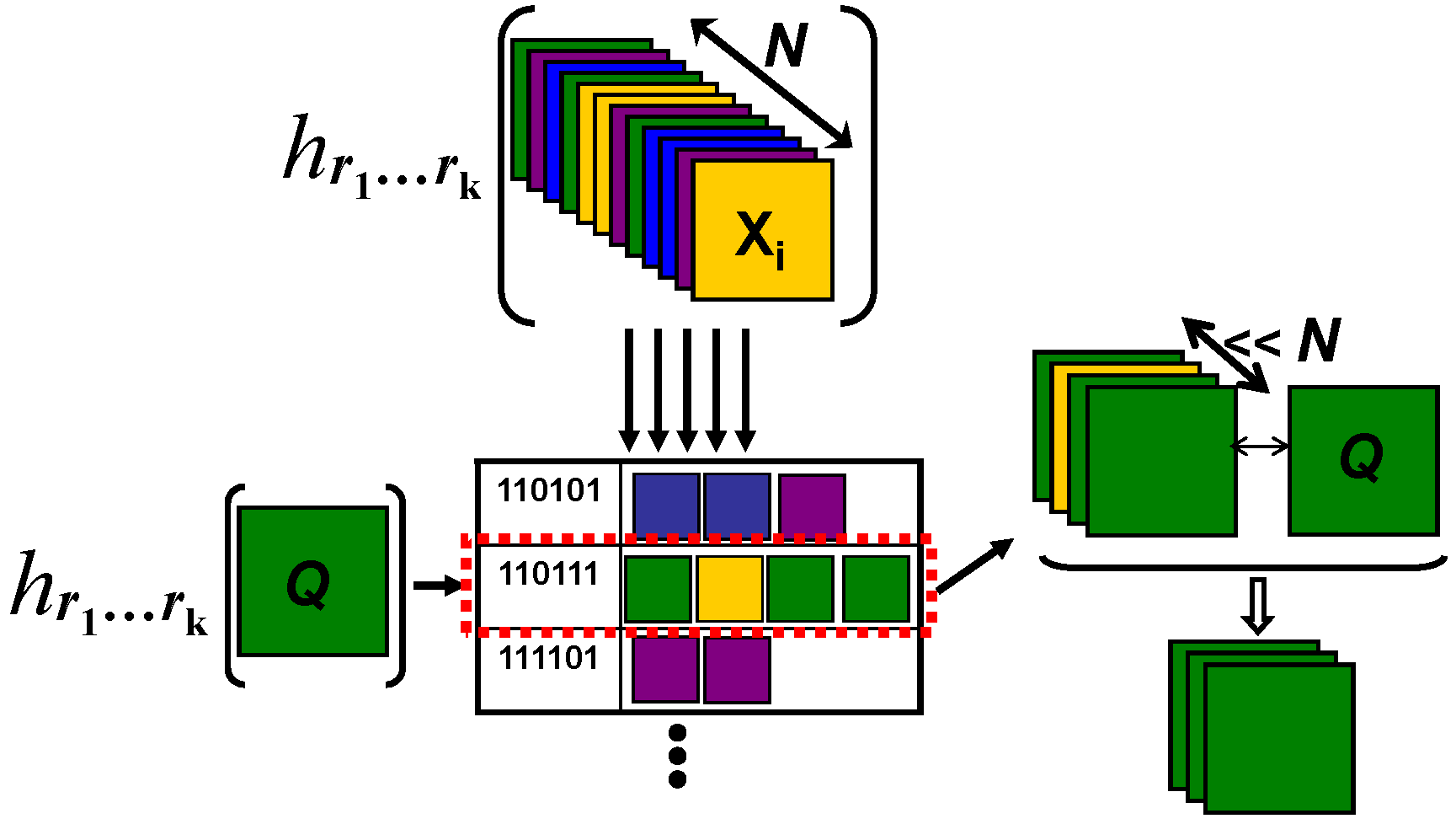
In this work, we present an LSH-based technique for performing fast similarity searches over arbitrary kernel functions. The problem is as follows: given a kernel function and a database of n objects, how can we quickly find the most similar item to a query object in terms of the kernel function? Like standard LSH, our hash functions involve computing random projections; however, unlike standard LSH, these random projections are constructed using only the kernel function and a sparse set of examples from the database itself. Our main technical contribution is to formulate the random projections necessary for LSH in kernel space. Our construction relies on an appropriate use of the central limit theorem, which allows us to approximate a random vector using items from our database. The resulting scheme, which we call kernelized LSH (KLSH), generalizes LSH to scenarios when the feature space embeddings are either unknown or incomputable.
Method
The main idea behind our approach is to construct a random hyperplane hash function, as in standard LSH, but to perform computations purely in kernel space. The construction is based on the central limit theorem, which will compute an approximate random vector using items from the database. The central limit theorem states that, under very mild conditions, the mean of a set of objects from some underlying distribution will be Gaussian distributed in the limit as more objects are included in the set. Since for LSH we require a random vector from a particular Gaussian distribution---that of a zero-mean, identity covariance Gaussian---we can use the central limit theorem, along with an appropriate mean-shift and whitening, to form an approximate random vector from a unit-mean, identity covariance Gaussian. By performing this construction appropriately, the algorithm can be applied entirely in kernel space, and can also be applied efficiently over very large data sets.
Once we have computed the hash functions, we use standard LSH techniques to retrieve nearest neighbors of a query to the database in sublinear time. In particular, we employ the method of Charikar for obtaining a small set of candidate approximate nearest neighbors, and then these are sorted using the kernel function to yield a list of hashed nearest neighbors.
There are some limitations to the method. The random vector constructed by the KLSH routine is only approximately random; general bounds on the central limit theorem are unknown, so it is not clear how many database objects are required to get a sufficiently random vector for hashing. Further, we implicitly assume that the objects from the database selected to form the random vectors span the subspace from which the queries are drawn. That said, in practice the method is robust to the number of database objects chosen for the construction of the random vectors, and behaves comparably to standard LSH on non-kernelized data.
Experimental Results
80 Million Tiny Images. We ran KLSH over the 80 million images in the Tiny Image data set. We used the extracted Gist features from these images, and applied a nearest neighbor search on top of a Gaussian kernel.
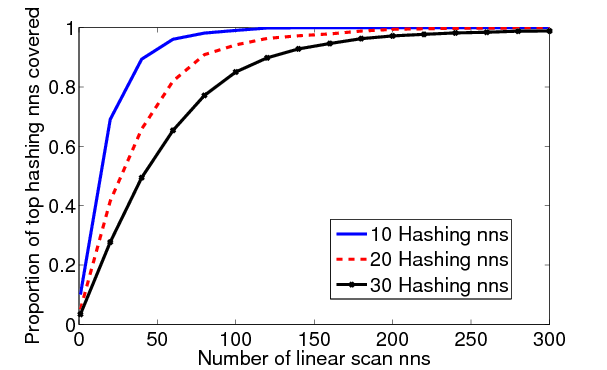
The top left image in each set is the query. The remainder of the top row shows the top nearest neighbor using a linear scan (with the Gaussian kernel) and the second row shows the nearest neighbor using KLSH. Note that, with this data set, the hashing technique searched less than 1 percent of the database, and nearest neighbors were extracted in approximately .57 seconds (versus 45 seconds for a linear scan). Typically the hashing results appear qualitatively similar to (or match exactly) the linear scan results.
We can see quantitatively how the results of the nearest neighbors extracted from KLSH compare to the linear scan nearest neighbors in the above plot. It shows, for 10, 20, and 30 hashing nearest neighbors, how many linear scan nearest neighbors are required to cover the hashing nearest neighbors.
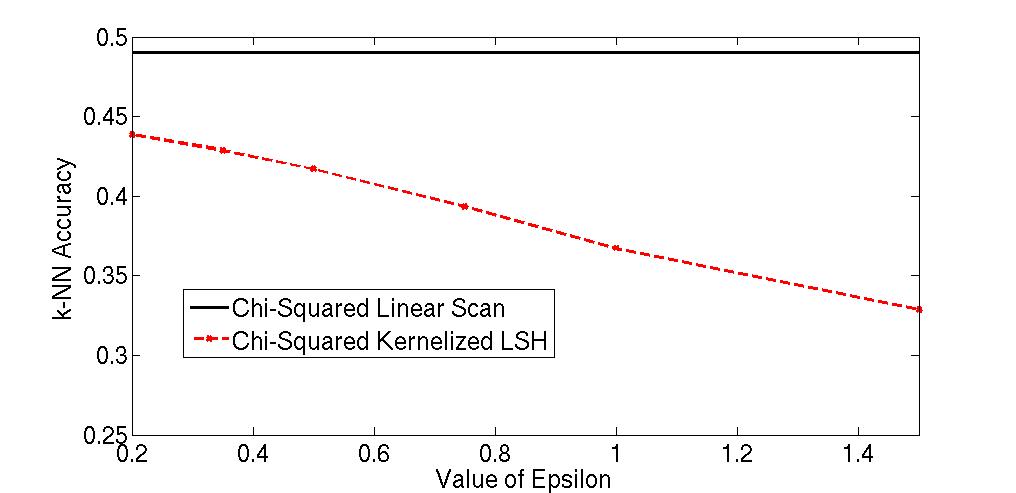
Flickr Scene Recognition. We performed a similar experiment with a set of Flickr images containing tourist photos from a set of landmarks. Here, we applied a chi-squared kernel on top of SIFT features for the nearest neighbor search. Note that these results did not appear in the conference paper.
We can also measure how the accuracy of a k-nearest neighbor classifier with KLSH approaches the accuracy of a linear scan k-NN classifier on this data set. The above plot shows that, as epsilon decreases, the hashing accuracy approaches the linear scan accuracy.
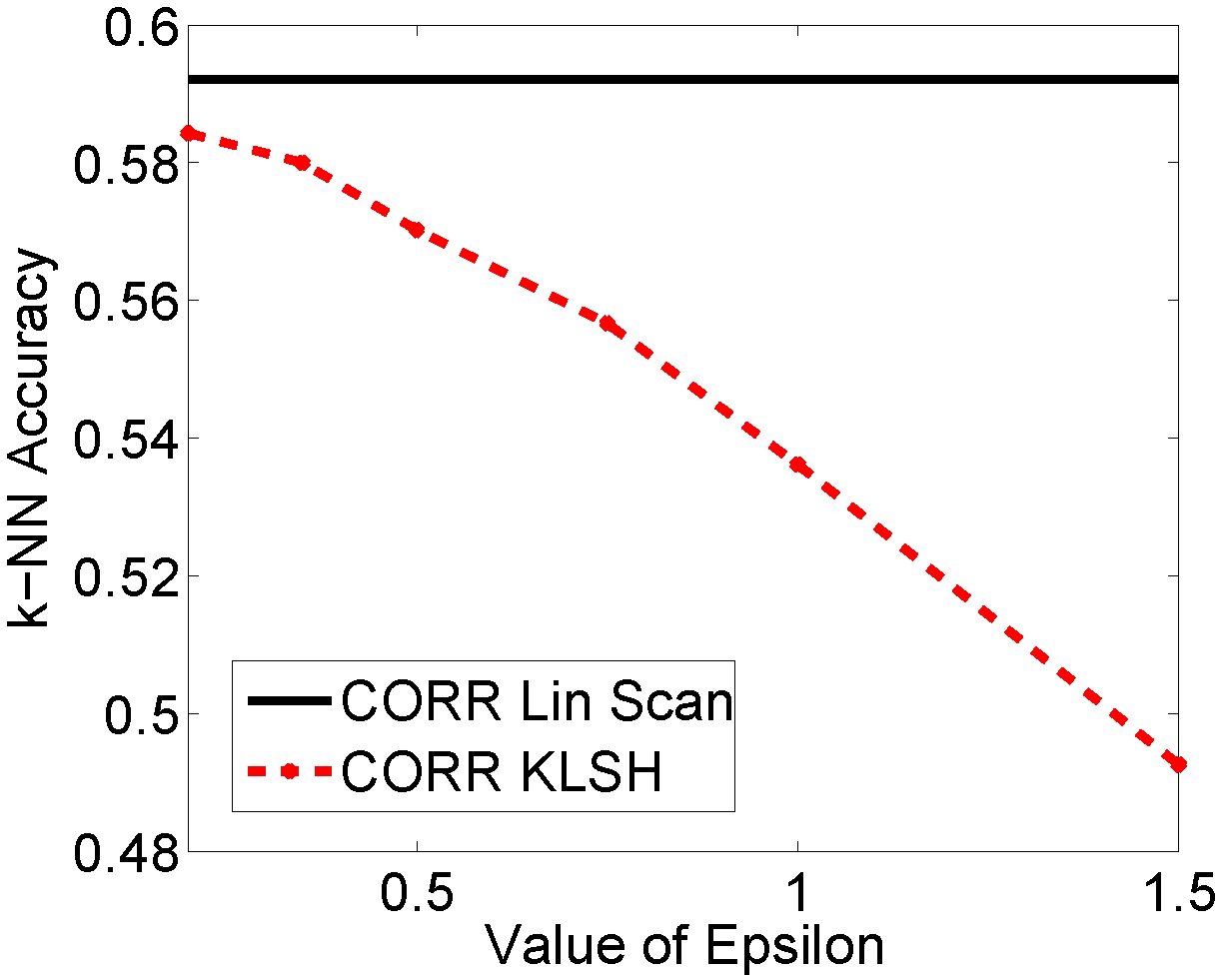
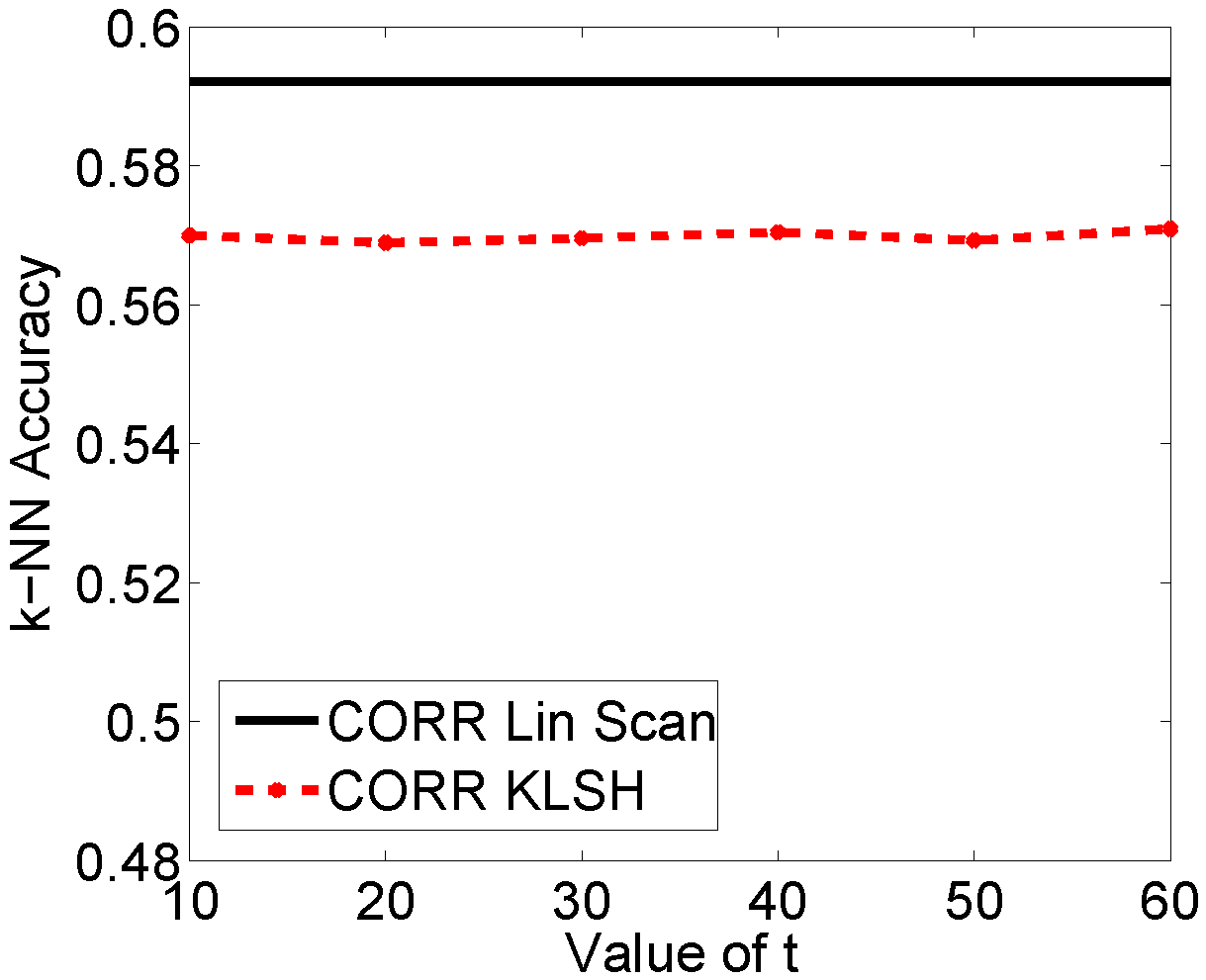
Object Recognition on Caltech-101. We applied our method on the Caltech-101 for object recognition, as there have been several recent kernel functions for images that have shown very good performance for object recognition, but have unknown or very complex featureembeddings. This data set also allowed us to test how changes in parameters affect hashing results.
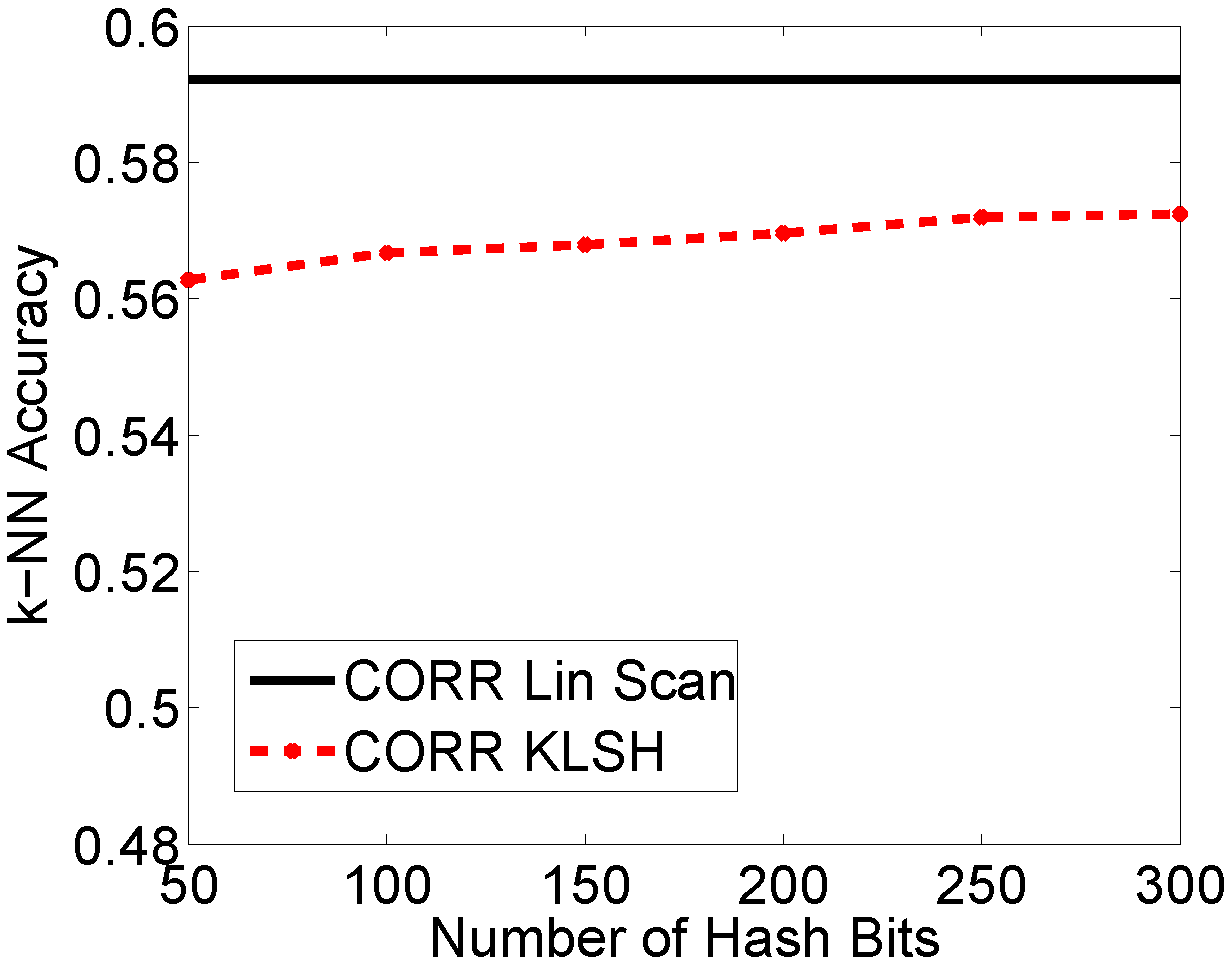
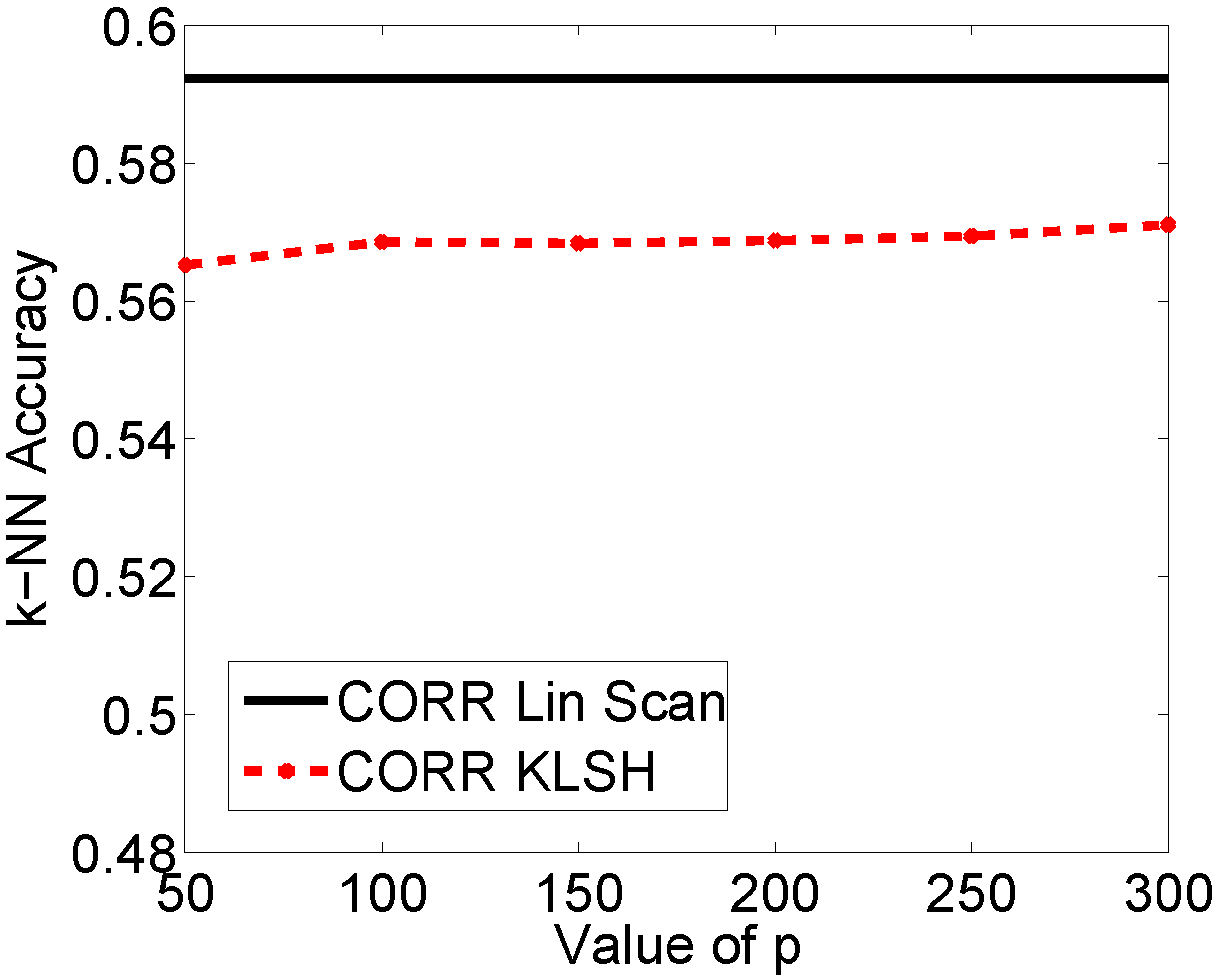
The parameters p, t, and the number of hash bits only affect hashing accuracy marginally. The main parameter of interest is epsilon, a parameter from standard LSH which trades off speed for accuracy.
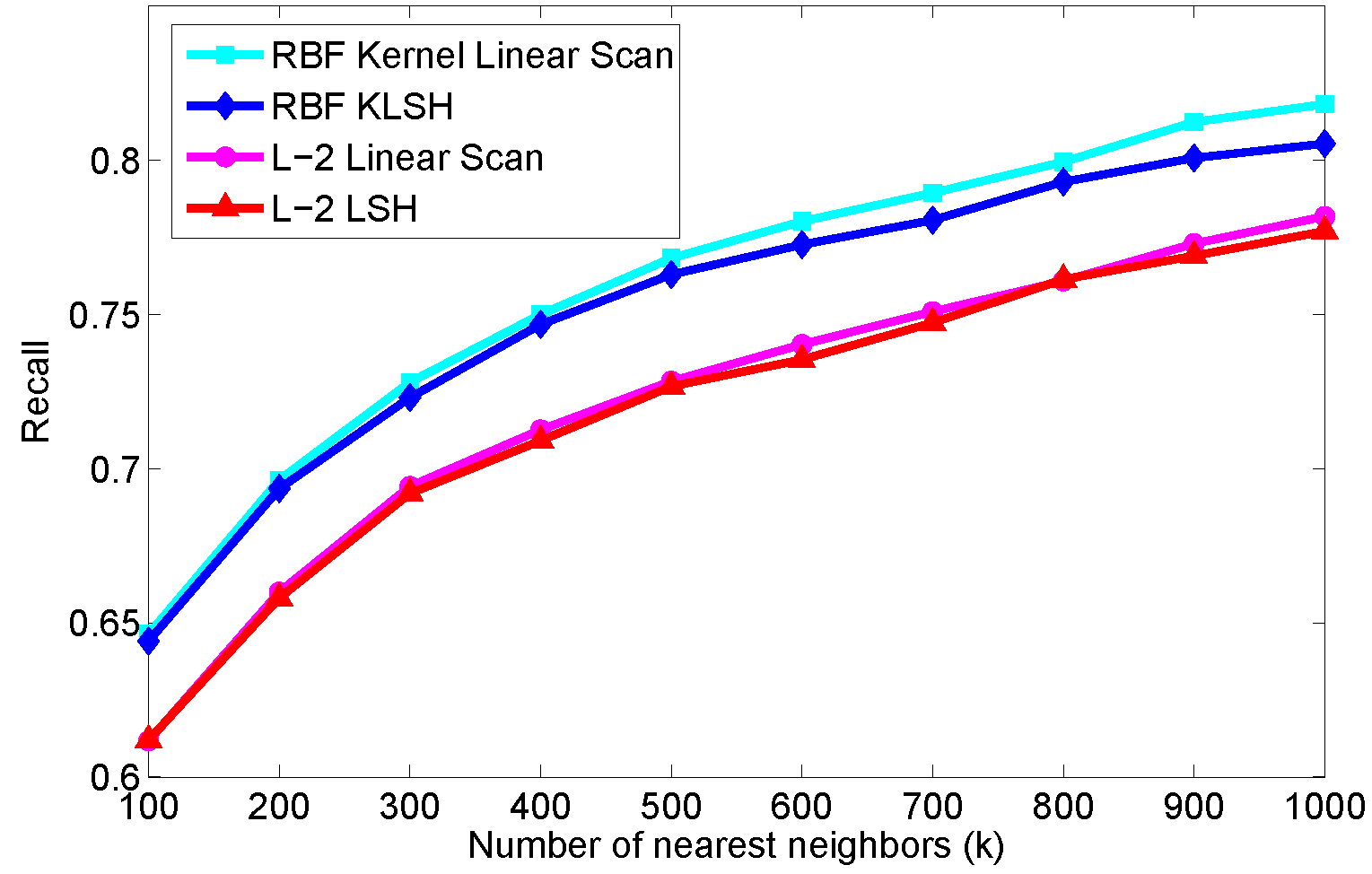
Local Patch Indexing with the Photo Tourism Data Set. Finally, we applied KLSH over a data set of 100,000 image patches from the Photo Tourism data set. We compared a standard Euclidean distance function (linear scan and hashing) with a learned kernel (linear scan and hashing). The particular learned kernel we used has no simple, explicit feature embedding (see the paper for details) but the linear scan retrieval results are significantly better than the baseline Euclidean distance, thus providing another example where KLSH is useful for retrieval. The results indicate that the hashing schemes do not degrade retrieval performance considerably on this data.
Summary. We have shown that hashing can be performed over arbitrary kernels to yield significant speed-ups for similarity searches with little loss in accuracy. In experiments, we have applied KLSH over several kernels, and over several domains:
Gaussian kernel (Tiny Images)
Chi-squared kernel (Flickr)
Correspondence kernel (Caltech-101)
Learned kernel (Photo Tourism)



Code
The code is available here. NOTE: the code was updated July 5, 2010 and September 23, 2010 to correct bugs in createHashTable.m. Please use the most recent version.
Paper
Kernelized Locality-Sensitive Hashing for Scalable Image Search
Brian Kulis & Kristen Grauman
In Proc. 12th International Conference on Computer Vision (ICCV), 2009.
[pdf]
Also see the following related papers, which apply LSH to learned Mahalanobis metrics:
Fast Similarity Search for Learned Metrics
Brian Kulis, Prateek Jain, & Kristen Grauman
IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 31, no. 12, pp. 2143--2157, 2009.
[pdf]
Fast Image Search for Learned Metrics
Prateek Jain, Brian Kulis, & Kristen Grauman
In. Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2008.
[pdf]